Forskellen mellem UMA og NUMA

Indhold

Multiprocessorer kan opdeles i tre kategorier med delt hukommelse - UMA (Uniform Memory Access), NUMA (Non-uniform Memory Access) og COMA (Cache-only Memory Access). Modellerne er differentierede baseret på, hvordan hukommelses- og hardware-ressourcerne distribueres. I UMA-modellen deles den fysiske hukommelse jævnt mellem processorerne, som også har samme latenstid for hvert hukommelsesord, mens NUMA giver variabel adgangstid for processorerne til at få adgang til hukommelsen.
Båndbredden, der bruges i UMA, til hukommelsen er begrænset, da den bruger en enkelt hukommelsescontroller. Det primære motiv for fremkomsten af NUMA-maskiner er at øge den tilgængelige båndbredde til hukommelsen ved hjælp af flere hukommelseskontrollere.
-
- Sammenligningstabel
- Definition
- Vigtige forskelle
- Konklusion
Sammenligningstabel
| Grundlag for sammenligning | UMA | NUMA |
|---|---|---|
| Grundlæggende | Bruger en enkelt hukommelseskontroller | Flere hukommelseskontrollere |
| Type anvendte busser | Enkelt, multiple og tværstang. | Træ og hierarkisk |
| Hukommelsestilgangstid | Lige | Ændringer i afhængighed af afstanden fra mikroprocessoren. |
| Egnet til | Generelle formål og tidsdelingsapplikationer | Realtid og tidskritiske applikationer |
| Hastighed | Langsommere | Hurtigere |
| båndbredde | Limited | Mere end UMA. |
Definition af UMA
UMA (Uniform hukommelsesadgang) systemet er en delt hukommelsesarkitektur for multiprocessorerne. I denne model bruges og fås adgang til en enkelt hukommelse af alle processorer, der præsenterer multiprocessorsystemet ved hjælp af samtrafiknetværket. Hver processor har samme hukommelsesadgangstid (latenstid) og adgangshastighed. Den kan anvende en af de enkelte bus-, multiple bus- eller tværstangskontakter. Da det giver afbalanceret adgang til delt hukommelse, er det også kendt som SMP (symmetrisk multiprocessor) systemer.
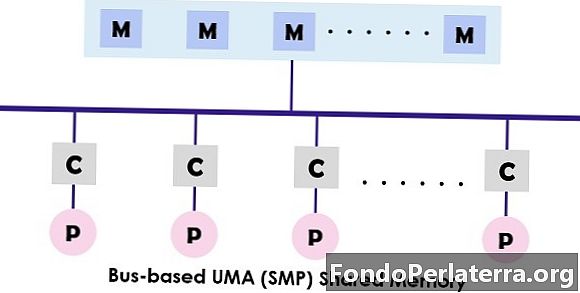
Det typiske design af SMP'en er vist ovenfor, hvor hver processor først er tilsluttet cachen, derefter cachen er knyttet til bussen. Endelig er bussen tilsluttet hukommelsen. Denne UMA-arkitektur reducerer busens stridighed ved at hente instruktionerne direkte fra den individuelle isolerede cache. Det giver også en lige sandsynlighed for læsning og skrivning til hver processor. De typiske eksempler på UMA-modellen er Sun Starfire-servere, Compaq alpha-server og HP v-serien.
Definition af NUMA
NUMA (ikke-ensartet hukommelsesadgang) er også en multiprocessormodel, hvor hver processor er forbundet med den dedikerede hukommelse. Imidlertid kombineres disse små dele af hukommelsen og skaber et enkelt adresserum. Det vigtigste punkt at overveje her er, at i modsætning til UMA, afhænger hukommelsens adgangstid på den afstand, hvor processoren er placeret, hvilket betyder varierende hukommelsesadgangstid. Det giver adgang til en hvilken som helst af hukommelsesplaceringen ved hjælp af den fysiske adresse.
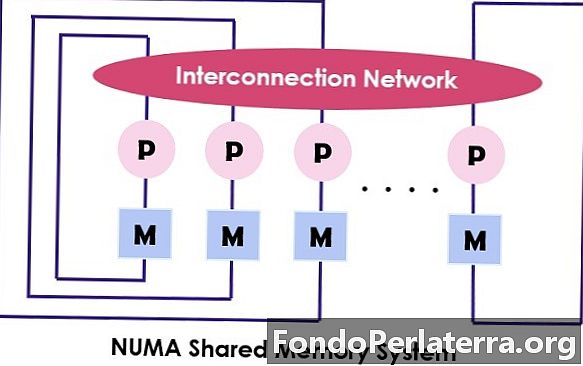
Som nævnt ovenfor er NUMA-arkitekturen beregnet til at øge den tilgængelige båndbredde til hukommelsen, og som den bruger flere hukommelseskontrollere til. Den kombinerer adskillige maskinkerner i “knuder”Hvor hver kerne har en hukommelseskontroller. For at få adgang til den lokale hukommelse i en NUMA-maskine henter kernen den hukommelse, der styres af hukommelsescontrolleren ved hjælp af dens knude. Mens adgang til fjernhukommelsen, der håndteres af den anden hukommelseskontroller, kører kernen hukommelsesanmodningen gennem sammenkoblingslinkene.
NUMA-arkitekturen bruger træ- og hierarkiske busnetværk til at forbinde hukommelsesblokke og processorer. BBN, TC-2000, SGI Origin 3000, Cray er nogle af eksemplerne på NUMA-arkitekturen.
- UMA-modellen (delt hukommelse) bruger en eller to hukommelseskontrollere. I modsætning til dette kan NUMA have flere hukommelseskontrollere til at få adgang til hukommelsen.
- Enkelt-, flere- og tværstangsbusser bruges i UMA-arkitektur. Omvendt bruger NUMA hierarkiske og trætype busser og netværksforbindelse.
- I UMA er hukommelsestilgangstiden for hver processor den samme, mens i NUMA ændres adgangstiden til hukommelse, når afstanden til hukommelsen fra processoren ændres.
- Generelle formål og tidsdelingsapplikationer er egnede til UMA-maskiner. I modsætning hertil er den passende anvendelse til NUMA centralt i realtid og tidskritisk.
- De UMA-baserede parallelle systemer fungerer langsommere end NUMA-systemerne.
- Når det kommer til båndbredde UMA, skal du have begrænset båndbredde. Tværtimod har NUMA båndbredde mere end UMA.
Konklusion
UMA-arkitekturen giver den samme samlede forsinkelse til de processorer, der får adgang til hukommelsen. Dette er ikke særlig nyttigt, når der er adgang til den lokale hukommelse, fordi latenstiden ville være ens. På den anden side havde hver processor i NUMA sin dedikerede hukommelse, hvilket eliminerer latenstiden, når der er adgang til den lokale hukommelse. Latensen ændres, når afstanden mellem processor og hukommelse ændres (dvs. ikke-ensartet). NUMA har imidlertid forbedret ydelsen sammenlignet med UMA-arkitektur.





